GENES OCULTOS EN EL ADN ‘BASURA’:
He tenido cierta adversion a Watson y Crick sobre la doble hélice que en 1953 revolucionó la biología : “Deseamos sugerir una estructura para la sal del ácido desoxirribonucleico (ADN)”. 
No mencionan a la Dra Franklin que en una fotografía , la numero 51, pudo fotografiar la doble hélice del ADN; y le robaron la idea de una manera deshonesta y a ella no la mencionó nadie. 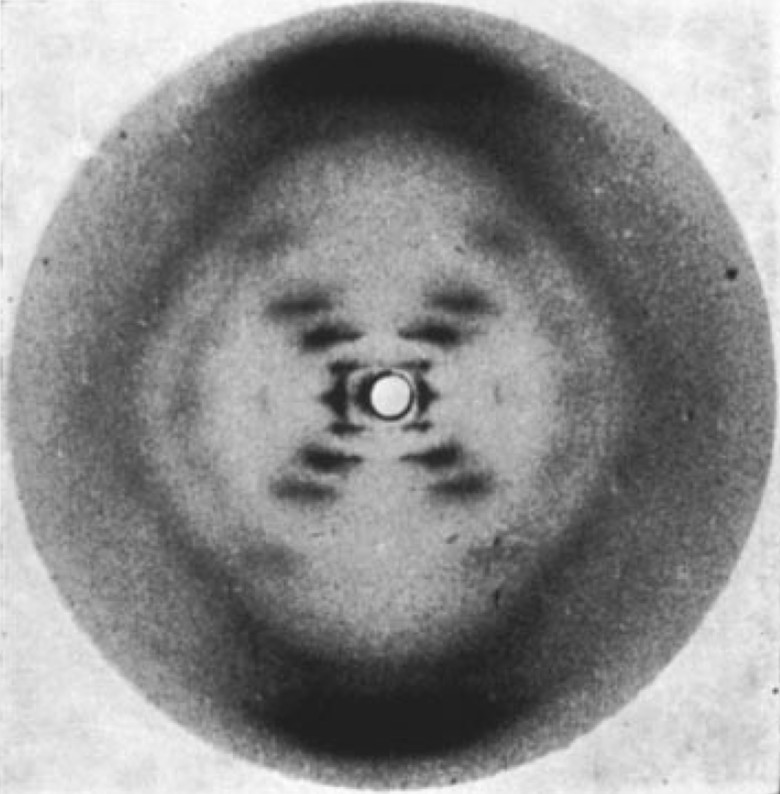
pero Watson y Crick, sabian la capacidad de codificar que tenia el ADN : “Proponemos que se requiere una reevaluación del genoma codificante humano (…) que podría tener grandes implicaciones en la salud y en las enfermedades humanas”.
Una porción de el 80%, no tenia función proyectiva, no fabricaba aminoácidos y se consideraban ‘basura’

Esta es la proteína Aw112010 que ha sorprendido a los biólogos. Procede de ADN catalogado como no codificante y, además, tiene funciones claras relacionadas con la inflamación en ratones. / Nature
El genoma, es todavía un país algo desconocido Aunque hace ya casi dos décadas que se publicó la primera secuencia prácticamente completa de nuestro ADN, los expertos no se ponen de acuerdo aún sobre cuántos genes tenemos con exactitud. Y la cosa acaba de complicarse un poco más: científicos de la universidad de Yale han confirmado en ratones la existencia de al menos un gen con su proteína asociada en lo que tiempo atrás se consideraba mero ADN basura.
En el año 2000 el Instituto Europeo de Bioinformática, el británico Ewan Birney, en el concurso GeneSweep ofrecia 3.000 dólares para quien acertara cuántos genes tenemos , todavía no se había publicado el primer borrador del Proyecto Genoma y participaron más de mil investigadores de todo el mundo: en promedio dijeron que teníamos 40.000, desde alguno que dijo unos 26.000 hasta otro que se fue más allá de los 312.000.
La definición de gen ha ido cambiando, se considera que es un segmento de ADN con la información necesaria para fabricar una proteína (previo paso intermedio por una molécula de ARN). Con esa asunción, ahora mismo se acepta que hay alrededor de 20.000 genes. Sin embargo, según un trabajo reciente firmado por varios investigadores españoles, seguramente haya un mínimo de 2.000 menos.
En algunos casos, lo que se llamó ‘ADN basura’ no solo marca el ritmo de la película, sino que también la protagoniza
Para filtrar de entre todo el ADN las partes candidatas a ser un gen, los científicos asumen al menos dos criterios: que comience por tres letras concretas y que tenga una longitud mínima antes de que aparezca una información de stop (un buen marco de lectura, en la jerga).
“Estos criterios eran muy restrictivos para predecir con precisión los genes codificadores de todo el genoma, una gran empresa que ha sido muy exitosa. Se necesitaban reglas fuertes para evitar cantidades enormes de errores”, comenta Ruahidri Jackson, primer firmante del nuevo trabajo. “Las reglas clásicas eran excelentes —añade—, pero, como con todas las reglas en biología, hay algunas excepciones”.
Desde hace tiempo se sospechaba que podía haber otras regiones del ADN dando lugar a lo que, por salirse de las reglas clásicas, se llamaron ‘productos proteináceos’. Ahora se ha demostrado por primera vez.
Si buena parte de lo que se llamó ‘ADN basura’ estaba en realidad activo y funcionaba regulando la acción de los genes a la manera de un director, resulta que hay casos en que los que no solo marca el ritmo de la película, sino que también la protagoniza. Contra la tendencia a la poda en el número de genes, aparecen ahora nuevos actores y funciones en lugares antes ignorados.
La universidad de Yale realizó lo que se conoce como una aproximación libre de hipótesis. Primero infectaron ratones de laboratorio con bacterias del tipo Salmonella y aislaron sus macrófagos, los glóbulos blancos de la sangre. Después hicieron el camino inverso a la investigación de búsqueda convencional.
.
El pilar central de la biología molecular dice que el ADN se transcribe a ARN y que este se traduce en proteínas dentro de los ribosomas, las verdaderas fábricas de la célula. En este caso, en lugar de estudiar directamente el ADN, se aprovecharon de una nueva técnica que permite aislar todo el ARN que ha llegado hasta estas fábricas y después desanduvieron el camino. Se trataba de observar, más que de predecir. Y eso puede acarrear sorpresas.
Cuando analizaron todo lo que pasaba, los números se agitaron. Hasta el 10 % del ARN tenía su origen en ADN no codificante. Para empezar, nunca debería haber llegado hasta allá. Pero eso no significa que esté dando lugar a proteínas, podría no ser funcional o degradarse nada más fabricarse.
En el ADN no codificante encontraron un gen que no solo daba lugar a una proteína, sino que esta era un mediador fundamental de la inflamación
Para buscar candidatos fiables en los que bucear, aplicaron unos criterios más laxos que los convencionales: fijaron una longitud mínima menor que la tradicional y se quedaron con aquellos que comenzaban con las cuatro combinaciones de letras más probables (en lugar de solo una).
Resultaron más de 200 candidatos y escogieron uno con el nombre (nada sexy) de Aw112010. Aprovechando las posibilidades de CRISPR —la nueva herramienta de edición genética— le hicieron todas las preguntas posibles y las respuestas fueron contundentes: no solo daba lugar a una proteína claramente identificable, sino que esta era un mediador fundamental de la inflamación, clave para que los ratones respondieran a la presencia de bacterias.
Si se impedía que esa proteína se formase, los animales acumulaban colonias de microorganismos que se diseminaban hacia el hígado y el bazo. Y al contrario: si se les provocaba una respuesta inflamatoria, como la que se produce en la enfermedad de Crohn o la colitis ulcerosa, su ausencia funcionaba como un factor protector. Aw112010 parece ser, realmente, un actor principal en una región antes olvidada.
“Este trabajo demuestra un caso concreto en que un ARN no codificante da lugar a una proteína y que esta tiene una función”, y reducia el número de genes en humanos a unos 2000.
Ampliación del campo de búsqueda
Aunque solo lo han demostrado en ratones, es muy probable que sea cierto para la mayoría animales y plantas, creen los investigadores
Los candidatos podrían ser incluso más. El análisis se ha hecho en un solo tipo de células y ante un estímulo concreto, por lo que otras variantes podrían despertar respuestas y genes diferentes.
Jackson reconoce que “se necesitarán nuevos y grandes estudios para determinar el significado del trabajo más allá de este gen”, pero trasluce optimismo: “Los estudios de proteómica han hallado durante mucho tiempo grandes cantidades de material proteico que no corresponde con lo conocido. Creo que este es un gran descubrimiento”.
David Juan, investigador en el Instituto de Biología Evolutiva de Barcelona